Comparing a Thai Words Segmentation Methods in the LST20 Dataset
DOI:
https://doi.org/10.14456/jcct.2024.7Keywords:
Thai Words, Segmentation Methods, LST20 DatasetAbstract
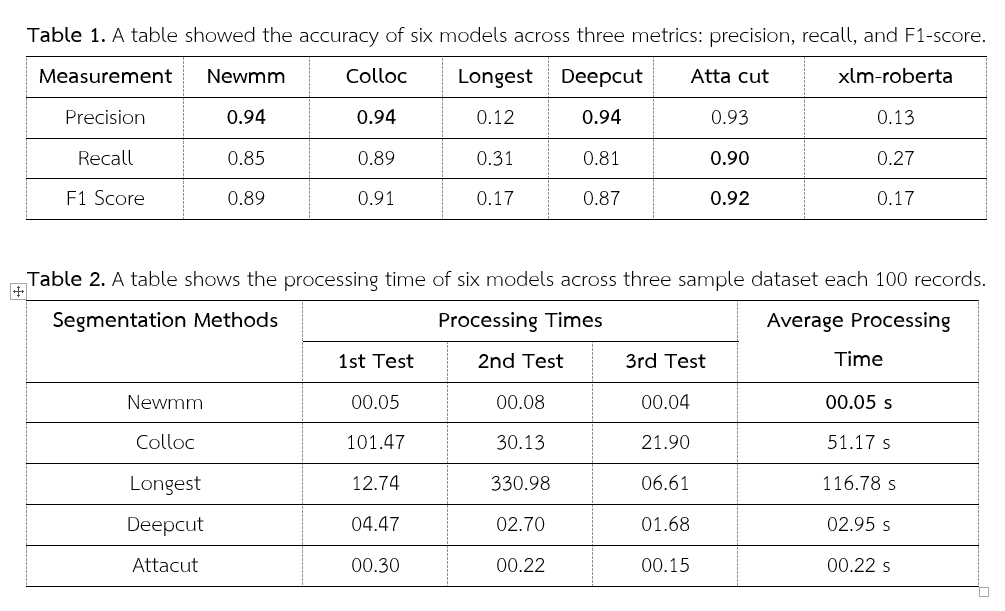
In this era of globalization where information is widely available, organizations are increasingly placing importance on using information to enhance their business. Although data is easily available, there are still challenges in natural language processing tasks, especially, the division of Thai words that lacks clarity of word boundaries, etc. This makes it difficult to identify the word groups in a sentence appropriately. Therefore, this study focuses on evaluating the performance of the word segmentation method including the Dictionary use and learning from data using evaluation of word segmentation in six techniques are important goals for the verification of the literal level accuracy and processing time of each method and technique, by the LST20 dataset contains 3,745 documents and covers 15 news categories in results show a more efficient way to learn from data.
Downloads
References
Aroonmanakun, W. (2002). Collocation and Thai Word Segmentation. Proceedings of SNLP-Oriental COCOSDA, 68-75. https://www.academia.edu/21349075/Collocation_and_Thai_Word_Segmentation.
Boonkwan, P., Luantangsrisuk, V., Phaholphinyo, S., Kriengket, K., Leenoi, D., Phrombut, C., Boriboon, M., Kosawat, K., & Supnithi, T. (2020). The Annotation Guideline of LST20 Corpus. ArXiv. https://doi.org/10.48550/ARXIV.2008.05055.
Chormai, P., Prasertsom, P., & Rutherford, A. (2019). AttaCut: A Fast and Accurate Neural Thai Word Segmenter. ArXiv. https://doi.org/10.48550/ARXIV.1911.07056.
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., Grave, E., Ott, M., Zettlemoyer, L., & Stoyanov, V. (2020). Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 8440–8451. https://doi.org/10.18653/v1/2020.acl-main.747.
De Vries, W., Wieling, M., & Nissim, M. (2022). Make the Best of Cross-lingual Transfer: Evidence from POS Tagging with over 100 Languages. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, 7676–7685. https://doi.org/10.18653/v1/2022.acl-long.529.
Haruechaiyasak, C., Kongyoung, S., & Dailey, M. (2008). A comparative study on Thai word segmentation approaches. 2008 5th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, 1, 125–128. https://doi.org/10.1109/ECTICON.2008.4600388.
Kittinaradorn, R., Chaovavanich, K., Achakulvisut, T., Srithaworn, K., Chormai, P., Kaewkasi, C., Ruangrong, T., & Oparad, K. (2019). DeepCut: A Thai Word Tokenization Library using Deep Neural Network. (v1.0). Zenodo. https://doi.org/10.5281/zenodo.3457707.
National Electronics and Computer Technology Center. (2022). LST20 Corpus. https://opend-portal.nectec.or.th/it/dataset/lst20-corpus. (In Thai)
Noyunsan, C., Haruechaiyasak, C., Poltree, S., & Saikaew, K.R. (2014). A Multi-Aspect Comparison and Evaluation on Thai Word Segmentation Programs. Joint International Conference of Semantic Technology. https://ceur-ws.org/Vol-1312/jist2014pd_paper6.pdf.
Poowarawan, Y. (1986). Dictionary-based Thai Syllable Separation. In Proceedings of the Ninth Electronics Engineering Conference, 409–418.
Ruenlek, K., & Damrongkamoltip, K. (2023). A Mockup Dataset for Word Segmentation Based on the LST20 Dataset. https://github.com/Fairpart/A-mockup-dataset-for-word-segmentation-based-on-the-LST20-DATASET.
Theeramunkong, T., Sornlertlamvanich, V., Tanhermhong, T., & Chinnan, W. (2000). Character Cluster based Thai Information Retrieval. Proceedings of the Fifth International Workshop on on Information Retrieval with Asian Languages, 75–80. https://doi.org/10.1145/355214.355225.
Virach, S. (1993). Word Segmentation for Thai in Machine Translation System. Machine Translation. 50-56. (In Thai)
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2024 Journal of Computer and Creative Technology

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.